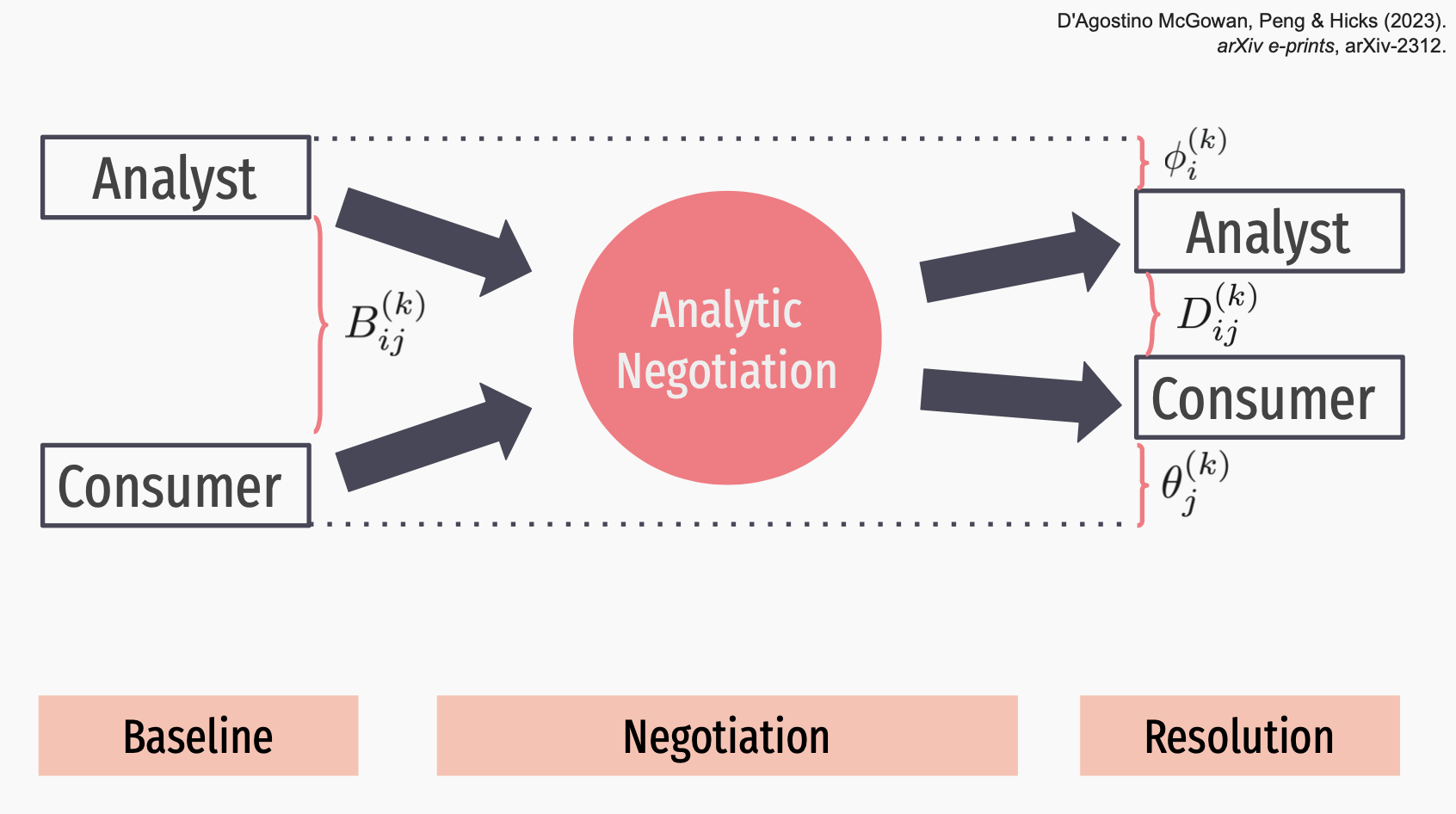
Missing data is a common challenge when analyzing epidemiological data, and imputation is often used to address this issue. In this talk, we investigate the scenario where covariates used in an analysis have missingness and will be imputed. There are recommendations to include the ultimate outcome in the imputation model for missing covariates, but it’s not necessarily clear when this recommendation holds and why this is true. We examine deterministic imputation (i.e., single imputation where the imputed values are treated as fixed) and stochastic imputation (i.e., single imputation with a random value or multiple imputation) methods and their implications for estimating the relationship between the imputed covariate and the outcome. We mathematically demonstrate that including the outcome variable in imputation models is not just a recommendation but a requirement to achieve unbiased results when using stochastic imputation methods. Moreover, we dispel common misconceptions about deterministic imputation models and demonstrate why the outcome should not be included in these models. This talk aims to bridge the gap between imputation in theory and practice, providing mathematical derivations to explain common statistical recommendations. We offer a better understanding of the considerations involved in imputing missing covariates and emphasize when it is necessary to include the outcome variable in the imputation model.